Комбинирование вычислений с доступом к памяти
В современных процессорах обращение к оперативной памяти уже не приводит к остановке вычислительного конвейера. Отослав чипсету запрос на загрузку ячейки процессор временно приостанавливает выполнение текущей машинной инструкции и переходит к следующей. Это обстоятельство, в частности, позволяет посылать очередной запрос чипсету до завершения предыдущего (см. "Параллельная обработка данных"). Однако параллелизм чипсета весьма невысок и при обработке больших объемов данных процессор все равно вынужден простаивать, ожидая загрузки ячеек из оперативной памяти. Так почему бы не избавить процессор от скуки, и не занять его вычислениями?
Предположим, нам необходимо загрузить N ячеек памяти и k раз вычислить синус угла. Предпочтительнее выполнять эти действия не последовательно, а объединить их в одном цикле. Тогда вычисления синуса будут происходить параллельно с загрузкой ячеек из памяти, сокращая тем самым время выполнения задачи.
Сразу же возникает вопрос: в какой именно пропорции целесообразнее всего смешивать вычисления и обращения к памяти? Достаточно очевидно, что в идеале время выполнения вычислительных инструкций должно быть равно времени загрузки ячеек из памяти, – в этом случае достигается наивысшая степень параллелизм. Проблема в том, что соотношение скорости доступа к памяти и скорости выполнения машинных инструкций на различных системах варьируется в очень широких пределах, и потому универсальных решений поставленной задачи нет. (см. подробное обсуждение эта проблемы в главе "Кэш Предвыборка"). С другой стороны, полного параллелизма добиваться вовсе не обязательно. Да и зачастую он вообще невозможен в принципе, – так, например, количества вычислений может оказаться просто недостаточно для покрытия всех задержек загрузки данных из памяти.
Попробуем оценить выигрыш, достигаемый при полном и частичном параллелизме. Для этого напишем следующую несложную тестовую программу, исследующую различные "концентрации" вычислительных операций на ячейку памяти.
Ниже для экономии места приведен лишь ее фрагмент. Обратите внимание: цикл, обращающийся к памяти, в оптимизированном варианте должен быть развернут. В противном случае, мы не получим никакого выигрыша в производительности, и хорошо если еще не окажемся в убытке. Почему? Так ведь свернутый цикл нельзя исполнять параллельно. Это, во-первых. А, во-вторых, циклы с небольшим количеством итераций крайне невыгодны хотя бы уже потому, что исполняются на одну итерацию больше, чем следует. (Стратегия предсказания ветвлений такова, что в последней итерации цикла процессор, не догадываясь о том, что цикл уже завершен, действует "как раньше", передавая управление на первую команду цикла; потом, конечно, он распознает свою ошибку и выполняет откат, но время выполнения от этого не уменьшается). Необходимость разворота циклов приводит к колоссальному увеличению размеров тестовой программы, – поскольку язык Си не поддерживает циклические макросы, весь код приходится набивать на клавиатуре вручную. Вот, кстати, хороший пример задачи которую невозможно элегантно решить штатными средствами языка Си (макроассемблер с этим бы справился на ура). Но довольно лирики, перейдем к исследованиям…
/* ---------------------------------------------------------------------------
не оптимизированный вариант
--------------------------------------------------------------------------- */
per=16; // 16 загружаемых байт на одно вычисление синуса
// цикл загрузки ячеек из памяти
// этот цикл исполняется крайне не оптимально, поскольку неповоротливая
// подсистема памяти просто не успевает за процессором и тому приходится скучать
for(a = 0; a < BLOCK_SIZE; a+=4)
z += *(int*)((int)p1 + a);
// цикл вычисления синусов
for(a=0; a < (BLOCK_SIZE/per); a++)
x+=cos(x);
/* ---------------------------------------------------------------------------
не оптимизированный вариант
--------------------------------------------------------------------------- */
// общий цикл, комбинирующий обращение к памяти с вычислениями синуса
for(a = 0; a < BLOCK_SIZE; a += per)
{
// внимание: цикл обращения к памяти должен быть развернут,
// иначе оптимизация обернется проигрышем в производительности
z += *(int*)((int)p1 + a);
z += *(int*)((int)p1 + a + 4);
z += *(int*)((int)p1 + a + 8);
z += *(int*)((int)p1 + a + 12);
// вычисление синуса будет происходить параллельно с загрузкой предыдущих
// ячеек за счет чего достигается увеличение производительности
x+=cos(x);
}
Листинг 27 [Memory/mem.mix.c] Фрагмент программы, демонстрирующей эффективность комбинирования обращения к памяти с выполнением вычислений
Прогон данной программы под системой AMD Athlon 1050/100/100/VIA KT133 (см. рис. graph 22) позволил установить, что наивысший параллелизм достигается, когда на каждые тридцать два загруженных байта приходится одна операция вычисления синуса. В этом случае оптимизированный вариант исполняется практически на треть быстрее. Еще больший выигрыш наблюдается на P-III/733/133/100/I815EP: при концентрации 256 байт на один синус, мы добиваемся чуть ли не двукратного увеличения производительности!
Правда, платой за это становится размер программы. Развернутый цикл из 64 команд загрузки данных смотрится, прямо скажем, диковато. Попытка же его свернуть съедает весь выигрыш производительности подчистую. Крайняя правая точка графика graph 22 (на диаграмме она отмечена символом звездочки) как раз и иллюстрирует такую ситуацию. Легко подсчитать, что на свертке цикла мы теряем не много, ни мало – 40% производительности, в результате чего оптимизированный вариант обгоняет не оптимизированный всего на 5%.
Впрочем, в подавляющем большинстве случаев быстродействие более критично, чем размер приложения, поэтому, никаких поводов для расстройства у нас нет.
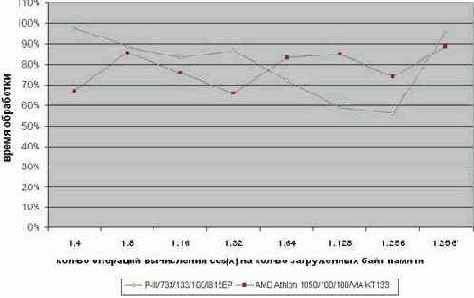
Рисунок 41 graph 22 Демонстрация эффективности комбинирования вычислительных операций с командами, обращающихся к памяти