Особенности кэш-подсистемы процессоров P-II и P-III
Несмотря на свою в общем-то далеко не передовую inclusive–архитектуру, кэш-подсистема процессора P-II, а уж тем более его преемника P-III, всухую уделывает Athlon, значительно обходя его в производительности.
Благодаря своей 256-битной шине, процессор P-III может загружать 32-байтовый пакет данных из кэша второго уровня всего за один такт, против девяти тактов, которые тратит на это Athlon (т.к. при ширине шины в 64бита протяженности кэш-линеек составляет 64 байта, а кэш второго уровня работает по формуле 2-1-1-1-1-1-1-1, в сумме мы и получаем 9 тактов). Взгляните на рис. 3, – видите, кривая чтения (она выделена синим цветом) на всем протяжении остается идеально горизонтальной и "ступеньки" между кэшем первого и второго уровней на ней нет! Эффективный размер кэша перового уровня процессора P-III равен размеру кэша второго уровня, что составляет 256 Кб! Terrific!!! Правда, с записью памяти дела обстоят не так благоприятно и некоторое падение производительности при выходе за границы кэша первого уровня все же наблюдается, но оно так мало, что им можно безболезненно пренебречь.
Интересно другое. Характер изменения кривой записи памяти при выходе за пределы кэша второго уровня на P-II и P-III носит ярко выраженный нелинейный
характер. Вместо стремительного падения производительности, имеющей место на K6 и Athlon, здесь она убывает крайне медленно, как бы нехотя, достигая насыщения лишь при достижении 1 Мб отметки, что вчетверо превышает размеры кэша второго уровня. Не правда ли, очень здорово!
Здорово оно, может быть и здорово, но вот за счет чего этот выигрыш достигается? Официальная документация, увы, не дает прямой ответа на этот вопрос, а сторонние руководства позорно уходят в кусы, объясняя происходящее "особенностями буферизации". Что же это за особенности такие – пускай разбираются сами читатели! И разберемся!
Секрет (впрочем, какой это теперь секрет) фирмы Intel состоит в том, что при записи ячеек памяти, соответствующие им линейки загружаются в кэш второго уровня как эксклюзивные.
Остальные же процессоры ( в частности, уже упомянутые Athlon и K6), напротив, помечают эти линейки как модифицируемые. Не знаю, раздерет ли меня Intel на клочки, но я все-таки рискну не только пустить пыль в глаза, но и подробно разъясню все вышесказанное.
Итак, мысленно представим, как происходит процесс записи ячейки, отсутствующей в кэш-памяти первого уровня. Если ни одного свободного буфера записи нет (а при интенсивной записи памяти их и не будет), процессор вынужден загружать модифицируемую ячейку в кэш первого уровня. Он посылает сигнал кэшу второго уровня, который считывает 32 байтный блок памяти в одну из своих строк, присваивает ей атрибут "эксклюзивная" и передает ее копию кэшу первого уровня. Так продолжается до тех пор, пока обрабатываемый блок не превысит размеров кэша первого уровня и тогда процессор будет вынужден избавиться от наименее нужной строки, чтобы освободить место для новой. Поскольку все строки модифицированы, выбирается наиболее старя из них и отправляется в кэш второго уровня. Поскольку, в кэше второго уровня уже есть ее копия, он просто обновляет содержимое соответствующей ей линейки и изменяет атрибут "эксклюзивный" на "модифицируемый".
А теперь мы дождемся момента, когда кэш второго уровня будет полностью заполнен, но процессор предпримет попытку записи еще одной ячейки. Что происходит? Кэш первого уровня отправляет кэшу второго уровня сразу два запроса: запрос на загрузку новой порции данных и запрос на обновление вытесняемой кэш-линейки, чем серьезно его озадачивает, – ведь свободное место уже исчерпано. Ага, – говорит кэш второго уровня, – сейчас мы выкинем самое ненужное. А что у нас ненужное? Правильно, – эксклюзивные строки. Их удаление не требует предварительной выгрузки в основную память, а потому и обходится дешевле. Тем временем, пока кэш второго уровня загружает новую порцию данных из оперативной памяти, строка, вытесненная из кэша первого уровня содержится в специальном буфере и в дальнейшем записывается в основную память минуя кэш второго уровня.
Ключевой момент истории состоит в том, что вновь загруженная порция данных получает атрибут эксклюзивной, что делает ее кандидатом номер один на вытеснение. Постойте! Но ведь это означает, что при выходе за пределы кэша второго уровня, записываемые данные будут замещать одну и ту же кэш-строку, сохраняя ранее записанные строки в неприкосновенности! Это выгодно отличает P-II, P-III от процессоров K6 и Athlon, в обработка блока, не умещающегося в кэше второго уровня, приводит к последовательному замещению всех его строк.
Допустим, размер записываемых данных вдвое превышает емкость кэш-памяти второго уровня. Тогда в K6 и Athlon кэш будет крутиться полностью вхолостую, а на P-II и P-III только половина обращений вызовет промахи, а остальная благополучно сохранится в кэше. Впрочем, если говорить объективно, это не совсем так. Вследствие ограниченной ассоциативности кэша постоянным перезагрузкам подвернется не одна-единственная строка, а целый банк.
Теперь, в свете вновь открывшихся обстоятельств, становится ясен характер кривой, сопровождающий выход обрабатываемого блока за границы кэша второго уровня. Действительно, сохранение части кэшируемой памяти как бы оттягивает момент насыщения, скругляя острые углы графика записи. Более того полное насыщение вообще не наступает, т.к. при любом конечном размере обрабатываемого блока, сколь бы большим он ни был, сохраненные строки в той или иной мере повышают производительность. Другой вопрос, что с ростом соотношения эффективность такой стратегии стремится к нулю и если размер обрабатываемого блока превосходит емкость кэша в четыре или более раз, ей можно пренебречь.
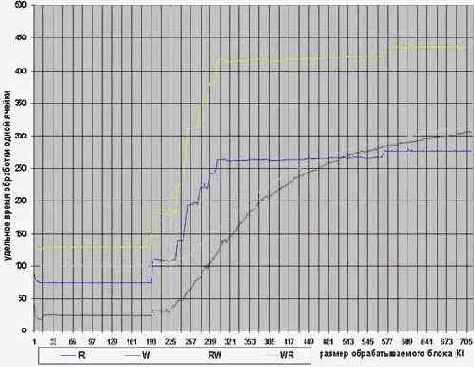
Рисунок 21 graph 3 Зависимость скорости обработки от размера блока на P-III
Чтение перед записью и запись перед чтением.
Операция записи ячейки с последующим ее чтением выполняется так же быстро, как и одиночная запись. Это не покажется удивительным, если вспомнить, что при промахе кэша первого уровня записываются данные временно сохраняются в буфере откуда они могут быть прочитаны в течение такта записи.
Другое дело – чтение с последующей записью. Тут, крути не крути, а при каждом промахе придется дожидаться пока данные не будут прочитаны из кэша второго уровня, в результате каждая операция требует по меньшей мере четырех дополнительных тактов. Измерения показывают, что так оно и есть.
На графике ??? изображены четыре кривые: ###синяя соответствует чтению тестируемого блока, фиолетовая – записи, желтая – чтению с последующей записью, а голубая – записью с последующим чтением.
Но вот ступенька пройдена и размер обрабатываемого блока становится таким большим, что не умещается в кэш-памяти второго уровня и мало-помалу начинает с нее "свешивается". График скоростного показателя чтения поднимается вверх и продолжает расти до тех пор, пока размер обрабатываемого блока не превысит емкости кэш-памяти первого уровня в 1.28 раза. Эта цифра хорошо согласуется с теоретическим значением – 1.25 (ассоциативность L2-кэша равна четырем). А вот три других графика ведут себя совсем не так, демонстрируя просто чудовищное падение производительности. Впрочем, этого и следовало ожидать – ведь промахи записи кэша второго уровня обходятся очень "дорого".