Уменьшение размера структур данных
Пусть у нас имеется некоторая структура данных (для определенности возьмем список), содержащая фиксированное количество элементов. Вопрос: имеет ли значение шаг чтения памяти, при условии, что каждый элемент обрабатывается однократно? Поскольку, минимальная порция обмена с памятью составляет, по меньшей мере, 32байта, а размеры элементов списка зачастую много меньше этой величины, становится очевидным, что скорость обработки обратно пропорциональна шагу обработки. Действительно, при чтении памяти через байт (слово, двойное слово) к половине загруженных ячеек вообще не происходит обращения, а при чтении памяти через четыре байта (слова, двойных слова) реально задействуется лишь 25% ячеек, а остальные загружаются "вхолостую". Отсюда следует, что данные в памяти следует располагать так плотно, как это только возможно. (см. так же "Оперативная память: выравнивание данных" и "Кэш: выравнивание данных").
Раздельные (separated) структуры данных.
Вернемся к списку. Классическое представление списка (см. рис. 0х33) – крайне не оптимально с точки зрения подсистемы памяти IBM PC. Почему? Да ведь при трассировке списка (трассировка – операция прохождения по списку без обращения к данным [значениям] его элементов) процессор вынужден загружать все ячейки, а не только ссылки на следующие элементы. Если операция трассировки выполняется неоднократно, – потери производительности могут оказаться весьма значительными.
Давайте реорганизуем нашу структуру данных, – указатели на следующий элемент поместим в один, а содержимое элементов – в другой массив. Теперь при трассировке списка (и большинстве других типовых операций с ним как то: определения количества элементов, поиск последнего элемента, замыкание и размыкание списков) окажутся востребованными все загруженные ячейки и, следовательно, эффективность обработки возрастет.
Обратите внимание: как в этом случае изменяется обращение к элементам списка. Если доступ к "классическому" списку осуществляется приблизительно так: _list[element].next=xxx; _list[element].val=xxx; то после его модернизации так: _mylist.next[element]=xxx; _mylist.val[element]=xxx.
Т.е. квадратные скобки сместились на одно слово вправо! Это не создает никаких неудобств (ну разве что с непривычки), но способно запутать начинающих программистов, не имеющих опыта работы с Си.
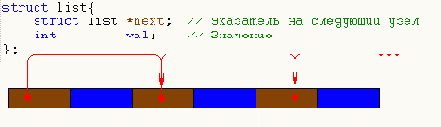
Рисунок 21 0х33 Устройство "классического" списка. При трассировке процессор вынужден загружать и ссылки, и значения, несмотря на то, что нас интересуют одни лишь ссылки
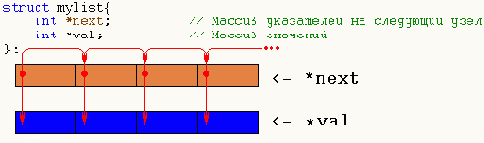
Рисунок 22 0х40 Устройство оптимизированного списка. Теперь при трассировке процессор загружает лишь те ячейки, к которым происходит реальное обращение, что значительно увеличивает производительность системы
В данном случае расщепление списка list в два раза сокращает объем памяти, загружаемый при его трассировке. И это еще не предел! Если количество элементов списка меньше полусотни тысяч (как чаще всего и бывает), разумно отказаться от 32-битных указателей и перейти на 16-битные индексы (см. рис. 34). Конечно, это не слишком-то продвинутый алгоритм, но его легко усовершенствовать! Выровняв все элементы в памяти по четным адресам, мы сможем задействовать младший бит указателя элемента под "производственные нужды". Скажем, если он равен нулю, то длина указателя 32 бит, а если единице, – то для представления адреса используется компактный 16 битный относительный указатель. Поскольку, расстояние между соседними элементами списка, как правило, невелико, нет нужды постоянно обращаться к ним по полному адресу, что экономит 16 бит на каждый элемент.
Развивая мысль дальше, можно ввести поддержку ситуаций "следующий элемент находится непосредственно за концом текущего" или "следующий элемент находится в другом списке". Конечная цель во всех этих случаях одна: вместо указателей с фиксированной разрядностью использовать указатели с "плавающей" разрядностью, занимающие минимальное возможное количество бит.
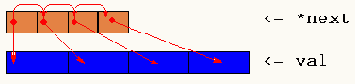
Рисунок 23 0х034. Отводите указателям минимально возможное количество бит, – это здорово сократит объем занимаемой памяти
Совместное использование обоих этих приемов (разделения списка вкупе с усечением разрядности указателей) сокращает размер ссылочного массива в sizeof(struct list)/sizeof(index_next) раз. Т.е. в данном случае – в четыре раза. Неплохо? А во сколько раз это повышает производительность? Давайте проверим! Рассмотрим следующую программу, реализующую "классический" и оптимизированный варианты списков и сравнивающую время их обработки.
/* -----------------------------------------------------------------------
*
* обработка классического списка
*
------------------------------------------------------------------------ */
struct list{ // КЛАССИЧЕСКИЙ СПИСОК
struct list *next; // Указатель на следующий узел
int val; // Значение
};
struct list *classic_list,*tmp_list;
// инициализация списка
for (a = 0; a < N_ELEM; a++)
{
classic_list[a].next= classic_list + a+1;
classic_list[a].val = a;
} classic_list[N_ELEM-1].next=0;
// трассировка списка
tmp_list=classic_list;
while(tmp_list = tmp_list[0].next);
/* ----------------------------------------------------------------------
*
* обработка оптимизированного раздельного списка
*
----------------------------------------------------------------------- */
struct mylist{ // ОПТИМИЗИРОВАННЫЙ РАЗДЕЛЬНЫЙ СПИСОК
short int *next; // Массив указателей на следующий узел
int *val; // Массив значений
};
struct mylist separated_list;
// инициализация списка
for (a=0;a<N_ELEM;a++)
{
separated_list.next[a] = a+1;
/* ^^^ обратите внимание где находятся
квадратные скобки */
separated_list.val[a] = a;
} separated_list.next[N_ELEM-1]=0;
// трассировка списка
while(b=separated_list.next[b]);
Листинг 13 [Memory/list.separated] Фрагмент программы, демонстрирующий эффективность трассировки разделенных списков
Результаты ее работы должны быть приблизительно следующими:
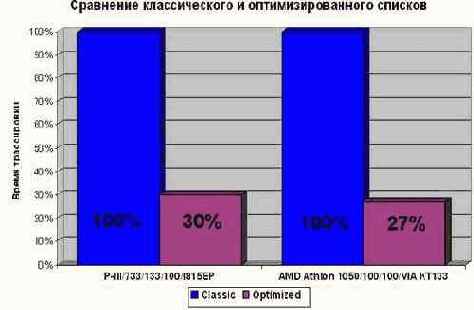
Рисунок 24 graph 0x08 Демонстрация эффективности обработки раздельных списков с указателями усеченной разрядности. Как видно, это значительно сокращает время трассировки списков, причем трехкратный выигрыш производительности (достигнутый в данном случае) – далеко не предел!
И впрямь, оптимизированный вариант оказался намного быстрее! Правда, не в четыре раза – как ожидалось – а всего лишь в три с половиной (обработка 16-разрядных значений на современных процессорах неэффективна), но и этим результатом по праву можно гордится! К тому же, если развернуть цикл и обрабатывать ссылки параллельно (см. "Параллельная обработка данных"), выигрыш будет еще большим!
Сложные случаи и капризы раздельной оптимизации.
Хорошо, а если у нас имеется структура вида (14), включающая в себя тело некоторого объекта (obj_body) и атрибуты объекта (obj_name). Пусть тело объекта занимает несколько килобайт, а его атрибуты – с пол сотни байт. Допустим так же, что нам необходимо написать функцию, обрабатывающую атрибуты всех объектов, но не трогающую тела этих самих объектов.
struct list_of_obj {
struct list_of_obj *next;
int obj_attr[14];
int obj_body[8000];
}
Листинг 14. Не оптимизированная структура
Имеет ли смысл помещать элементы такой структуры в раздельные массивы? Давайте подсчитаем. Длина пакетного цикла обмена в подавляющем большинстве случаев составляет 32 (K6/P-II/P-III) или 64 байта (Athlon). Сумма длин полей obj_attr и obj_body – 60 байт. Следовательно, всего лишь ~10% загруженных ячеек остаются невостребованными. Это весьма незначительная потеря и ей, по идее, можно безболезненно пренебречь. Но, прежде чем делать окончательный вывод, не поленимся, а сравним оптимизированный и не оптимизированный варианты на практике.
/* -----------------------------------------------------------------------
*
* обработка классического списка
*
------------------------------------------------------------------------ */
struct LIST_OF_OBJ { // НЕОПТИМИЗИРОВАННЫЙ СПИСОК
struct LIST_OF_OBJ *next; // указатель на следующий объект
int obj_attr[ATTR_SIZE]; // атрибуты объекта /нечто компактное
int obj_body[BODY_SIZE]; // тело объекта /нечто монстровое
};
struct LIST_OF_OBJ *list_of_obj, *tmp_list_of_obj;
// выделение памяти
list_of_obj = (struct LIST_OF_OBJ*)
_malloc32(N_ELEM*sizeof(struct LIST_OF_OBJ));
// инициализация списка
for (a = 0; a < N_ELEM; a++)
list_of_obj[a].next = list_of_obj + a + 1; list_of_obj[N_ELEM-1].next = 0;
// трассировка списка
tmp_list_of_obj = list_of_obj;
do{
for(attr = 0; attr < ATTR_SIZE; attr++)
x += tmp_list_of_obj[0].obj_attr[attr];
} while(tmp_list_of_obj = tmp_list_of_obj[0].next);
/* ----------------------------------------------------------------------
*
* Обработка оптимизированного раздельного списка
*
----------------------------------------------------------------------- */
struct LIST_OF_OBJ_OPTIMIZED { // ОПТИМИЗИРОВАННЫЙ СПИСОК
struct LIST_OF_OBJ_OPTIMIZED *next; // указатель на следующий объект
#ifdef PESSIMIZE
int *obj_attr; // указатель на атрибуты (это плохо!)
#else
int obj_attr[ATTR_SIZE]; // атрибуты объекта (это хорошо!)
#endif
int *obj_body; // указатель на тело объекта
};
struct LIST_OF_OBJ_OPTIMIZED *list_of_obj_optimized, *tmp_list_of_obj_optimized;
// выделение памяти
list_of_obj_optimized = (struct LIST_OF_OBJ_OPTIMIZED*)
_malloc32(N_ELEM*sizeof(struct LIST_OF_OBJ_OPTIMIZED));
// инициализация списка
for
(a = 0; a
< N_ELEM ;a++)
{
list_of_obj_optimized[a].next = list_of_obj_optimized + a + 1;
#ifdef PESSIMIZE
list_of_obj_optimized[a].obj_attr = malloc(sizeof(int)*ATTR_SIZE);
#endif
list_of_obj_optimized[a].obj_body = malloc(sizeof(int)*BODY_SIZE);
} list_of_obj_optimized[N_ELEM-1].next = 0;
// трассировка списка
tmp_list_of_obj_optimized = list_of_obj_optimized;
do{
for(attr = 0; attr < ATTR_SIZE; attr++)
x+ = tmp_list_of_obj_optimized[0].obj_attr[attr];
} while(tmp_list_of_obj_optimized = tmp_list_of_obj_optimized[0].next);
Листинг 15 [Memory/list.obj.c] Фрагмент программы, демонстрирующий эффективность оптимизации структуры (14)
Ого! Оптимизированный вариант обгоняет своего "классического" коллегу в скорости на целых 60% (см. рис. graph 9), – весьма существенный прирост производительности, не так ли? К сожалению, оптимизированный вариант весьма капризен. Если заменить оптимизированную структуру (14):
struct list_of_obj_optimized {
struct list_of_obj_optimized *next;
int obj_attr[ATTR_SIZE];
int *obj_body;
};
на ее ближайший аналог:
struct list_of_obj_optimized {
struct list_of_obj_optimized *next;
int *obj_attr;
int *obj_body;
};
…то разница между оптимизированным и не оптимизированным вариантом составит всего лишь 30%!!! (см. рис. graph 9). Совершенно непонятно: чем же int *obj_attr хуже, чем int obj_attr[ATTR_SIZE]?! И тем более непонятно, за счет чего в последнем случае достигается такая производительность. Мистика прям какая-то! Ведь, исходя из самых общих соображений, ясно: количество загруженных ячеек памяти во всех случаях должно быть одинаково!
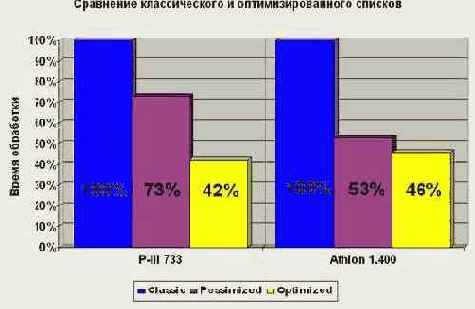
Рисунок 25 graph 0x09 Демонстрация эффективности различных подходов к оптимизации структуры (14) Учет особенностей станичной организации памяти (см. ниже) позволяет более чем в два раза сократить время обработки списка
Учитывайте станичную организацию памяти. Ненадолго оторвемся от этой маленькой головоломки и исследуем зависимость времени трассировки списка от шага чтения памяти. Казалось бы, какие тут могут быть сюрпризы? А вот попробуйте с ходу объяснить форму кривой, полученной с помощью программы list.step.c.
// перебор различных значений шага чтения памяти
for(a = STEP_FACTOR; a < MAX_STEP_SIZE; a += STEP_FACTOR)
{
#ifdef UNTLB
// загрузка страниц в TLB
for (i=0;i<=BLOCK_SIZE;i+=4*K) x += *(int *)((int)p + i+32);
#endif
L_BEGIN(0); // <-- начало замера времени выполнения
i=0;
// чтение памяти с шагом a
for(b = 0; b < MAX_ITER; b++)
{
x += *(int *)((int)p + i);
i
+= a;
}
L_END(0); // <-- конец замера времени выполнения
}
Листинг 16 [Memory/list.step.c] Фрагмент программы, демонстрирующий зависимость времени трассировки списка от шага чтения памяти
Кривая (см. рис. graph 0x007) и впрямь ведет себя очень интересно. Время трассировки – вопреки всем прогнозам – не остается постоянным, а увеличивается вместе с шагом! Правда, это увеличение не бесконечно, – при достижении отметки в 32 Кб для P-II\P-III и 64 Кб для AMD Athlon, кривая достигает максимума насыщения и переходит в горизонтальное "плато", превышающее "подножье" по высоте более чем в пять раз! Это слишком большая величина, и мы не можем просто взять и проигнорировать ее, но… чем же, черт побери, вызван рост времени обработки?! Конечно, оперативная память неоднородна и время доступа к ней непостоянно, но чтобы она была настолько
неоднородна.…
Какой физической реальности соответствует отметка в 32 Кб (а на Athlon и вовсе в 64 Кб)? Структур такого размера в памяти (насколько мы знаем память) заведомо нет. Между тем, время обработки при увеличении шага растет.
Почему? Можно конечно, отступиться от этой проблемы ("знаете, процессор – эта такая сложная вещь…" как ответили автору в службе технической поддержки), но ведь она так и останется "занозой" в теле и будет ныть. Нет уж, разбираться – так разбираться!
Если немного доработать программу, заставив ее выводить время доступа к каждой ячейке, то обнаружиться (см. [Memory/memory.way.c]), что через каждые четыре килобайта кривая внезапно изгибается в неприступный зубец (см. рис. graph 10), "отъедающий" десятки тысяч тактов процессора! Нет, это не типографская ошибка. Все так и должно быть, – ведь практически все современные операционные системы (и Windows с UNIX в том числе) используют страничную организацию памяти. Не останавливаясь подробно на этом вопросе (см. "Intel Architecture Software Developer's Manual Volume 3 System Programming Guide", §3.6 PAGING") отметим лишь тот факт, что с каждой страницей связана специальная 32?битная структура данных, содержащая атрибуты страницы и ее базовый адрес. При первом обращении к странице процессор считывает эти данные из физической памяти в свой внутренний буфер (именуемый TLB – Translation Look aside Buffer) и последующие обращения к той же самой станице происходят без задержек вплоть до вытеснения этой информации из TLB. Так вот где собака порылась! Оказывается, минимальной порцией обмена с памятью является отнюдь не 32-байтный пакетный цикл, а целая страница! Время задержки, возникающей при первом обращении к странице, лишь в полтора-два раза уступают времени чтения всей этой страницы, – т.е. независимо от количества реально прочитанных байт, обработка страницы занимает столько времени, как если она была прочитана целиком. Отсюда, – потоковые алгоритмы должны обращаться как можно к меньшему количеству страниц, т.е. в пределах одной страницы располагайте данные максимально плотно, не оставляя пустот.
Но постойте, постойте! Ведь если это предположение верно (а оно верно), насыщение должно наступать уже при четырех килобайтом шаге.
Действительно, чем шаг в восемь или двенадцать килобайт хуже четырех? Во всех трех случаях загрузка атрибутов страниц происходит на каждой итерации, т.е. цикл выполняется максимально неэффективно. Между тем, кривая, перевалив за четыре килобайта, пусть и уменьшает свой наклон (на P-III уменьшение наклона практически незаметно, но все же есть) и упорно продолжает свой рост. Почему?!
Дело в том, что атрибуты страниц не разбросаны хаотично по всей памяти, а объединены в особые структуры – Page Table (Страничные Таблицы или Таблицы страниц). Каждый элемент страничной таблицы занимает одно двойное слово, но, так как минимальная порция обмена с памятью превышает эту величину, то при обращении к одной странице процессор загружает из памяти атрибуты еще семи (пятнадцати – в Athlon) страниц, сохраняя эту информацию в сверхоперативной памяти. Вот вам и ответ на вопрос! Умножение восьми (пятнадцати) элементов на четыре (размер одной страницы в килобайтах) как раз и дает те загадочные 32 (64 на Athlon) килобайта, ограничивающие рост кривой.
Теперь становится понятно, почему вынос obj_body в отельный массив значительно ускорил обработку списка, – элементы *next и obj_attr стали располагаться плотнее и уместились в меньшее количество страниц.
Почему вынос obj_attr ухудшил производительность – понять несколько сложнее. Количество страниц, правда, в последнем случае будет несколько больше, но ненамного. Давайте подсчитаем. Первый вариант структуры занимает (sizeof(*next) + sizeof (int) * ATTR_SIZE + sizeof(*obj_body)) * N_ELEM = 64 Кб (16 страниц). Второй вариант: (sizeof(*next) + sizeof(*obj_attr) + sizeof(*obj_body)) * N_ELEM + sizeof(int) * ALIGN_ATTR_SIZE * N_ELEM = 76 Кб (19 страниц). Ну, пусть за счет округления набежит еще пара страниц. Тогда 21/16 = 1.3, в то время как соотношения производительности первого и второго вариантов составляет 1.4 для Athlon и аж 1.8 для P-III. Куда уходят такты?! А вот куда. Стратегия выделения памяти функции malloc такова, что при запросе маленьких блоков каждый последующий выделенный блок имеет меньший адрес, чем предыдущий.
Т.е. элементы страничного каталога читаются в обратном направлении, а пакетный цикл памяти – в прямом. Как следствие, процессору приходится дольше ожидать получения атрибутов "своей" страницы, – стоит ли удивляться снижению производительности?
Подытоживая все вышесказанное, сформулируем следующее правило: для достижения максимальной производительности все станицы, к которым происходит обращение, следует использовать целиком. Причем, страницы должны запрашивается в порядке возрастания их линейных адресов.
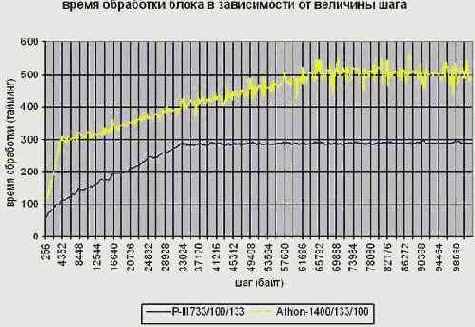
Рисунок 26 graph 0х007 График, иллюстрирующий время обработки блока данных в зависимости от шага чтения. На P-III насыщение наступает на 32 Кб шаге чтение данных, а на AMD Athlon – на 64 Кб. Причем, на участке (0; 4Кб] происходит резкий "влет" кривой, особенно хорошо заметный на AMD Athlon.
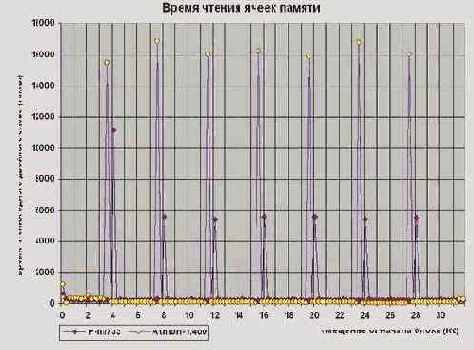
Рисунок 27 graph 10 График, иллюстрирующий зависимость времени доступа к ячейке от адреса этой ячейки при последовательном обращении к данным. Смотрите, – при первом обращении к странице возникает пауза в десятки тысяч тактов!