Устранение зависимостей по данным
Если запрашиваемые ячейки оперативной памяти имеют адресную зависимость по данным (т.е. попросту говоря, одна ячейка содержит адрес другой), процессор не может обрабатывать их параллельно, и вынужден простаивать в ожидании поступления адресов. Рассмотрим это на следующем примере: while(next=p[next]). До тех пор, пока процессор не узнает значение переменной next, он не сможет приступить к загрузке следующей ячейки, т.к. еще не знает ее адреса. Время выполнения такого цикла определяется в основном латентностью подсистемы памяти и практически не зависит от ее пропускной способности. И SDRAM, и DDR-SDRAM, и даже сверхпроизводительная RDRAM покажут практически одинаковый результат, над которым посмеялась бы и EDO-DRAM, будь одна до сих пор жива. Латентность же подсистемы памяти на современных компьютерах весьма велика и составляет приблизительно 20 тактов системной шины, что соответствует полному времени доступа в 200 нс.
Прямую противоположность этому составляет цикл вида: while(a=p[next++]). Процессор, отправив чипсету запрос на загрузку ячейки p[next], немедленно увеличивает next на единицу и, не дожидаясь ответа (зачем? ведь адрес следующей ячейки известен), посылает чипсету еще один запрос. Потом еще один, и еще.… Так продолжается до тех пор, пока количество необработанных запросов не достигает своего максимально допустимого значения (для P6 – четырех). Поскольку, запросы следуют друг за другом с минимальным интервалом, в первом приближении можно считать, что они обрабатываются параллельно. И это действительно так! Если время загрузки N зависимых ячеек в общем случае равно: t = N(Tch + Tmem), где Tch – латентность чипсета, а Tmem – латентность памяти, то такое же количество независимых ячеек будут загружены за время , где C – пропускная способность подсистемы памяти.
Таким образом, при обработке независимых данных пагубное влияние латентности подсистемы памяти в значительной мере ослабляется, и производительность определяется исключительно пропускной способностью.
Правда, достичь заявленного производителем количества мегабайт в секунду таким способом все равно не удастся (ведь число одновременно обрабатываемых запросов ограничено и полного параллелизма в этой схеме не достигается), но полученный результат будет, по крайней мере, не худшего порядка.
Наглядно сравнить скорость обработки зависимых и независимых данных позволяет следующая программа:
/* ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
*
* цикл чтения зависимых данных
* (не оптимизированный вариант)
* ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– */
for (a=0; a < BLOCK_SIZE; a += 32)
{ /* ^^^^^ мы разворачиваем цикл для более быстрой обработки */
// читаем ячейку
x = *(int *)((int)p1 + a + 0);
// адрес следующей ячейки вычисляется на основе значения предыдущей
// поэтому, процессор не может послать очередной запрос чипсету до тех пор,
// пока не получит эту ячейку в свое распоряжение
a += x;
// дальше - аналогично...
y = *(int *)((int)p1 + a + 4);
a += y;
x = *(int *)((int)p1 + a + 8);
a += x;
y = *(int *)((int)p1 + a + 12);
a += y;
x = *(int *)((int)p1 + a + 16);
a += x;
y = *(int *)((int)p1 + a + 20);
a += y;
x = *(int *)((int)p1 + a + 24);
a += x;
y = *(int *)((int)p1 + a + 28);
a
+= y;
}
/* ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
*
* цикл чтения независимых данных
* (оптимизированный вариант)
* ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– */
for (a=0; a<BLOCK_SIZE; a += 32)
{
// теперь процессор может посылать очередной запрос чипсету,
// не дожидаясь завершения предыдущего, т.к. адрес ячейки
// никак не связан с обрабатываемыми данными
x += *(int *)((int)p1 + a + 0);
y += *(int *)((int)p1 + a + 4);
x += *(int *)((int)p1 + a + 8);
y += *(int *)((int)p1 + a + 12);
x += *(int *)((int)p1 + a + 16);
y += *(int *)((int)p1 + a + 20);
x += *(int *)((int)p1 + a + 24);
y += *(int *)((int)p1 + a + 28);
}
Листинг 9 [Memory/dependence.c] Фрагмент программы, демонстрирующий эффективность обработки независимых данных
Результат тестирования двух компьютеров, имеющихся в распоряжении автора, представлен на рис. graph 1. Первое, что сразу бросается в глаза – значительный разрыв во времени обработки зависимых и независимых данных. В частности, на P?III/733/133/100 цикл чтения независимых данных выполняется в два с половиной раза быстрее! Несколько худший результат показывает AMD Athlon?1050/100/133/VIA KT 133, что объясняется серьезными конструктивными недоработками этого чипсета (см. "Вычисление полного времени доступа"). Недостаточная пропускная способность канала между контроллером памяти и блоком интерфейса с шиной (оба смонтированы в северном мосте чипсета) приводит к образованию постоянных заторов, и как следствие – ограничению количества одновременно обрабатываемых запросов. Тем не менее, даже в этом случае чтение независимых данных осуществляется намного эффективнее и весь вопрос в том, как именно следует их обрабатывать.
Линейное (оно же – последовательное) чтение ячеек памяти – не самая удачная идея, что и демонстрирует рис. graph 1. На P-III мы не достигли и 60% от расчетной пропускной способности, а на AMD Athlon и того меньше, – всего лишь немногим более 30%. "Потрясающая" производительность, не правда ли? Это что же такое получается?! Неужели архитектура PC настолько крива, что не позволяет справиться даже с такой простой штукой как оперативная память? Кстати, мы не первые, кому эта "здравая" мысль пришла в голову.У большинства прикладных разработчиков существует весьма устойчивое убеждение, что PC – это тормоз. По жизни. Но не спешите пересаживаться на Cray…
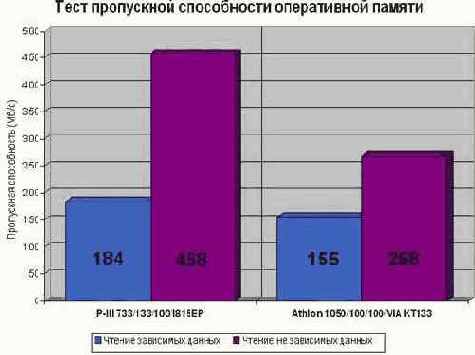
Рисунок 18 graph 0x001 Тест пропускной способности оперативной памяти при линейном чтении зависимых и независимых данных. На "правильном" чипсете Intel 815EP независимые данные обрабатываются в два с половиной раза быстрее. На чипсете VIA KT133 (за счет его высокой латентности) различие в производительности намного меньше и составляет всего 1,7 крат. Но, как бы так ни было, на любой системе обрабатывать зависимые данные крайне невыгодно. Обратите также внимание, что при линейном чтении данных заявленная пропускная способность (800 Мб/сек. для данного типа памяти) не достигается