Увеличение эффективности предвыборки.
Предотвращение "холостого" хода. Сдвиг предвыборки на несколько итераций приводит к возникновению "холостого" хода – неэффективному исполнению первых psd проходов цикла, ввиду отсутствия запрашиваемых данных в кэше и вытекающей отсюда необходимостью ожидания их загрузки из медленной основной памяти. Если цикл исполняется многократно (скажем, сто или даже сто тысяч раз), накладные расходы настолько невелики, что вряд ли кому придет в голову брать их в расчет. Если же цикл исполняется несколько десятков раз, то время его выполнения практически не сказывается на производительности системы, и им можно вновь пренебречь. Однако если такой цикл вызывается неоднократно (скажем, из другого цикла), то потери от холостого хода окажутся весьма внушительными.
Рассмотрим следующий пример:
for (a = 0; a < N; a++)
{
for (b = 0; b < BLOCK_SIZE; b+=STEP_SIZE)
{
// Для переноса примера на K6\Athlon замените
// нижеследующую инструкцию на prefetch
_prefetchnta (p[a][b+STEP_SIZE]);
computation (a[a][b]);
}
}
Листинг 24 Пример, демонстрирующий "холостой" ход предвыборки
Поскольку, дистанция предвыборки цикла B равна единице, то первый проход цикла всегда исполняется неэффективно – "вхолостую". При небольшом значении BLOCK_SIZE и внушительном N с этим трудно смириться! А при дистанции предвыборки сравнимой с количеством итераций цикла B ее эффективность и вовсе стремится к нулю. Точно такая же ситуация наблюдается и на P-4, механизм аппаратной предвыборки которого не настолько интеллектуален, чтобы справиться с вложенными циклами.
Как, не сильно усложнив алгоритм, увеличить его производительность? Да очень просто – достаточно лишь в последней итерации цикла B осуществить предвыборку следующей обрабатываемой ячейки. В данном случае ею будет ячейка p[a+1][0].
Оптимизированный вариант кода может выглядеть, например, так:
for (a = 0; a < N; a++)
{
for (b = 0; b <BLOCK_SIZE; b+=STEP_SIZE)
{
if (b==(BLOCK_SIZE-STEP-SIZE))
_prefetchnta (p[a+1][0]);
else
_prefetchnta (p[a][b+STEP_SIZE]);
computation (p[a][b]);
}
}
Листинг 25 Черновая демонстрация удаление "холостого" хода предвыборки
Однако использование ветвлений в теле цикла не самым лучшим образом сказывается на его производительности, поэтому условный переход следует выкинуть, переписав код, например, так:
for (a = 0; a < N; a++)
{
for (b = 0; b <(BLOCK_SIZE-STEP_SIZE); b+=STEP_SIZE)
{
_prefetchnta (p[a][b+STEP_SIZE]);
computation (p[a][b]);
}
_prefetchnta (p[a+1][0]);
computation (p[a][b]);
}
Листинг 26 Финальная демонстрация удаления "холостого" хода предвыборки
После модернизации программы, останется не устраненным всего лишь один холостой проход, возникающий при первом выполнении цикла В (точнее, не устраненными останутся psd проходов), что даже при небольшом N практически не сказывается на производительности.
Уменьшение количества инструкций предвыборки. Все предыдущие рассуждения молчаливо опирались на предположение, что шаг цикла равен размеру кэш-линейки, а в реальной жизни так бывает далеко не всегда. Наглядной демонстрацией тому следует следующий пример:
int p[N];
#define computation (x) zzz+=(x)*0x666; zzz+=p[x];
for (a = 0; a < N; a+=sizeof(int))
{
_prefetchnta (p[a + 32*3]);
computation (a);
}
Листинг 27 Демонстрация чрезмерного злоупотребления предвыборкой
Поскольку каждый элемент массива p занимает всего лишь 8 байт, а размер кэш-линеек процессора в зависимости от модели составляет от 32 до 128 байт, в большинстве итераций цикла команда предвыборки будет выполняться вхолостую, т.к. запрошенные данные уже находятся в кэше, и загружать из оперативной памяти их не требуется. В такой ситуации команда предвыборка ведет себя аналогично инструкции NOP, однако накладные расходы на ее выполнение отнюдь не равны нулю! Чрезмерное засорение цикла предвыборкой (overprefetching) не то, что не ускоряет, а даже замедляет
его работу. В частности, пример??? 8 при исключении предвыборки исполняется на 10%-15% быстрее! (см. рис. 0х019). (Следует так же учесть накладные расходы на передачу аргументов функции предвыборки).
Решение проблемы заключается в разворачивании цикла с подгонкой величины его шага к размеру кэш-линий. Это снизит накладные расходы на выполнение цикла и удалит все лишние предвыборки, в результате чего скорость выполнения кода значительно возрастет. Так, оптимизация предыдущего примера увеличивает скорость его выполнения на 80%, т.е. более чем в три раза:
for (a = 0; a < N; a+=32)
{
_prefetchnta (p[a + 32*3]);
computation (a+0);
computation (a+4);
computation (a+8);
computation (a+12);
computation (a+16);
computation (a+20);
computation (a+24);
computation (a+28);
}
Листинг 28 [cache_prefetch_unroll] Разворачивание цикла для исключения лишних запросов предвыборки
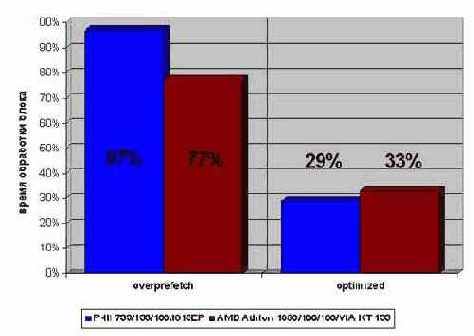
Рисунок 47 graph 0x019 Влияние лишних запросов предвыборки на производительность. За 100% приятно копирование памяти штатной функцией memcpy
Однако этот прием не лишен недостатков: во-первых, многократное дублирование тела цикла приводит к значительному увеличению объема исполняемого кода с вытекающим отсюда риском попросту не влезть в кэш. Во-вторых, величину шага (а, значит, и размер кэш-линеек) допустимо выбирать лишь на этапе создания программы и поменять ее "на лету" практически невозможно. Чем плоха "жесткая" прошивка? Дело в том, что, попав на процессор с иной длиной кэш-линий, программа будет исполняться недостаточно эффективно. Ориентироваться на размер в 32 байта – это хвататься за процессоры уходящего дня, но затачивать свой код под 128 байт – все равно, что бежать впереди паровоза. Рабочие станции на основе P-4 вытеснят P?III не раньше чем через несколько лет, но и тогда доля процессоров с 32 (64) байтными кэш-линейками будет весьма велика. Похоже, ничего не остается, как реализовать все критичные к быстродействию функции в нескольких вариантах и по ходу выполнения программы выбирать одну из них.
Но почему бы ни вставить в цикл тривиальный условный оператор, например, что-то вроде: if ((a % PREFETCH_CACHE_LINE_SIZE) == 0) prefetch(a+psd)? Во?первых, деление крайне
медленная операция и поэтому такой прием снизит производительность цикла на столько, что и домкратом ее не поднимешь. Во-вторых, даже если исхитриться и заменить деление битовыми операциями (или ввести в цикл дополнительный счетчик) накладные расходы будут по-прежнему довольно велики. Лучше уж остановить свой выбор на 32-байтных кэш-линейках, махнув рукой на оптимизацию под P-4 и более старшие процессоры, которые и без того быстры, а вот их младшим братьям требуется поддержка.
Мясной рулет предвыборки на инструкциях. До сих пор мы рассматривали случаи предвыборки лишь одной кэш-линейки за каждую итерацию цикла, но если параллельно обрабатывается несколько блоков памяти, расположенных в различных местах, одной операцией предвыборки уже не обойтись. Конечно, лучше всего – организовать структуру данных так, чтобы совместно используемые данные находились как можно ближе друг к другу, - в идеале вообще в пределах единой кэш-линейки. Но, увы, это не всегда возможно… Тогда, если уменьшить количество предвыборок невозможно, следует по крайней мере увеличить эффективность их выполнения.
Рассмотрим следующий пример:
for (a = 0; a < N; a+=32)
{
computation1 (p1[a]);
computation2 (p2[a]);
computation3 (p3[a]);
computation4 (p4[a]);
}
Листинг 29 Не оптимизированный пример, демонстрирующий обработку четырех различных ячеек памяти за каждую итерацию
При условии, что блоки памяти p1, p2, p3 и p4 расположены достаточно далеко друг от друга, требуется как минимум четыре инструкции предвыборки на каждую итерацию. Возникает вопрос – как лучше всего их расположить: поместить их в начало цикла или перемешать вместе с остальными инструкциями?
Вопрос не имеет однозначного ответа – каждый прием имеет свои сильные и слабые стороны, и чему отдать предпочтение зависит от конкретной ситуации.
С одной стороны, большое количество подряд идущих запросов на предвыборку, приводит к чрезмерной загруженности как системной, так и внутренней шины процессора и образованию "затора" в load- и fill-буферах. В результате, выполнение инструкций, обращающихся к данным, приостанавливается, даже если эти данные расположены в кэше первого уровня! Поэтому, предвыборку лучше перемежевать с вычислительными инструкциями, чтобы они без напряги для шины могли исполняться параллельно. С другой стороны, это утверждение верно лишь в отношении вычислительных инструкций, но не команд записи! Для достижения наивысшей производительности системы настоятельно рекомендуется до минимума сократить количество транзакций между чтением и записью данных.
Таким образом, стратегия оптимального размещения команд предвыборки значительно усложняется. В первом приближении она выглядит так: если тело цикла состоит исключительно из вычислительных инструкций, ничего не записывающих в память, команды предвыборки лучше всего равномерно перемещать вместе с остальными инструкциями. Если же в теле цикла присутствуют команды записи, то попытайтесь скомбинировать код так, чтобы транзакции записи и чтения не пересекались.
Т.е. предвыборку с инструкциями записи должно разделять, по крайней мере, 30-50, а лучше еще большее количество тактов процессора. А что делать, если это невозможно? В таком случае будет лучше сгруппировать все операции предвыборки вместе, чем позволить им перемешаться с операциями записи. Вообще-то оптимальное чередование можно подобрать и экспериментально, только помните о том, что оно системно-зависимо.