Взаимодействие памяти и процессора
Вопреки распространенному заблуждению процессор взаимодействует с оперативной памятью не напрямую, а через специальный контроллер, подключенный к системной шине процессора приблизительно так же, как и остальные контроллеры периферийных устройств. Причем, механизм обращения к портам ввода/вывода и к ячейкам оперативной памяти с точки зрения процессора практически идентичен. Процессор сначала выставляет на адресную шину требуемый адрес и в следующем такте уточнят тип запроса: происходит ли обращение к памяти, портам ввода/вывода или подтверждение прерывания. В некотором смысле оперативную память можно рассматривать как совокупность регистров ввода/вывода, каждый из которых хранит некоторое значение.
Обработка запросов процессора ложится на набор системной логики (так же называемый чипсетом) среди прочего включающий в себя и контроллер памяти. Контроллер памяти полностью "прозрачен" для программиста, однако знание его архитектурных особенностей существенно облегчает оптимизацию обмена с памятью.
Рассмотрим механизм взаимодействия памяти и процессора на примере чипсета Intel 815. Когда процессору требуется получить содержимое ячейки оперативной памяти он, дождавшись освобождения шины, через механизм арбитража захватывает шину в свое владение (что занимает один такт) и в следующем такте передает адрес искомой ячейки. Еще один такт уходит на уточнение типа запроса, назначение уникального идентификатора транзакции, сообщение длины запроса и маскировку байтов шины. Подробнее об этом можно прочитать в спецификациях на шины P6 и EV6, здесь же достаточно отметить, что эта фаза запроса осуществляется за три такта системной шины.
Независимо от размера читаемой ячейки (байт, слово, двойное слово) длина запроса всегда равна размеру линейки L2-кэша (подробнее об устройстве кэша мы поговорим в одноименной главе), что составляет 32 байта для процессоров K6/P-II/P-III, 64 байта – для AMD Athlon и 128 байт – для P-4. Такое решение значительно увеличивает производительность памяти при последовательном чтении ячеек, и практически не уменьшает ее при чтении ячеек вразброс, что и неудивительно, т.к.
латентность чипсета в несколько раз превышает реальное время передачи данных и им можно пренебречь.
Контроллер шины (BIU – Bus Interface Init), "вживленный" в северный мост чипсета, получив запрос от процессора, в зависимости от ситуации либо передает его соответствующему агенту (в нашем случае – контроллеру памяти), либо ставит запрос в очередь, если агент в этот момент чем-то занят. Потребность в очереди объясняется тем, что процессор может посылать очередной запрос, не дожидаясь завершения обработки предыдущего, а раз так – запросы приходится где-то хранить.
Но, так или иначе, наш запрос оказывается у контроллера памяти (MCT – Memory Controller). В течение одного такта он декодирует полученный адрес в физический номер строки/столбца ячейки и передает его модулю памяти по сценарию, описанному в главе "Устройство и принципы функционирования оперативной памяти".
В зависимости от архитектуры контроллера памяти он работает с памятью либо только на частоте системной шины (синхронный контроллер), либо поддерживает память любой другой частоты (асинхронный контроллер). Синхронный контролеры ограничивают пользователей ПК в выборе модулей памяти, но, с другой стороны, асинхронные контроллеры менее производительны. Почему? Во-первых, в силу несоответствия частот, читаемые данные не могут быть непосредственно переданы на контроллер шины, и их приходится сначала складывать в промежуточный буфер, откуда шинный контроллер сможет их извлекать с нужной ему скоростью. (Аналогичная ситуация наблюдается и с записью). Во-вторых, если частота системной шины и частота памяти не соотносятся как целые числа, то перед началом обмена приходится дожидаться завершения текущего тактового импульса. Таких задержек (в просторечии пенальти) возникает две: одна – при передаче микросхеме памяти адреса требуемой ячейки, вторая – при передаче считанных данных шинному контроллеру. Все это значительно увеличивает латентность подсистемы памяти – т.е. промежутка времени с момента посылки запроса до получения данных.
Таким образом, асинхронный контроллер, работающий с памятью SDRAM PC-133 на 100 MHz системной шине, проигрывает своему синхронному собрату, работающему на той же шине с памятью SDRAM PC-100.
Контроллер шины, получив от контроллера памяти уведомление о том, что запрошенные данные готовы, дожидается освобождения шины и передает их процессору в пакетном режиме. В зависимости от типа шины за один такт может передаваться от одной до четырех порций данных. Так, в процессорах K6, P-II и P-III осуществляется одна передача за такт, в процессоре Athlon – две, а в процессоре P-4 – четыре.
Все! С этого момент данные поступают в кэш и становятся доступными процессору.
>>>>> Врезка.
Большинство наборов системных логик состоит из двух микросхем – северного
и южного мостов. Северный мост (названный так за свое традиционное расположение на чертежах) включает в себя контроллер системной шины процессора, контроллер памяти, факультативно контроллер порта AGP, PCI-контроллер или контроллер внутренней шины для общения с южным мостом. Южный мост отвечает за ввод/вывод и включает в себя контроллер DMA, контроллер прерываний, таймер, контроллеры жестких и гибких дисков, последовательных-, параллельных- и USB-портов.
<<<<<
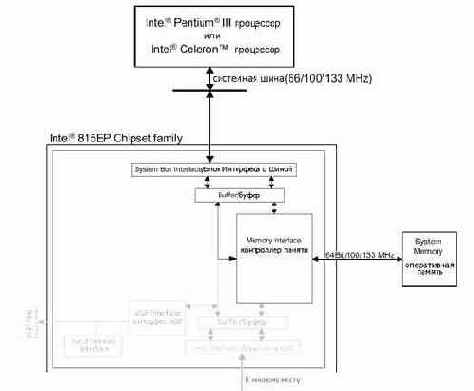
Рисунок 11 0х27 Устройство серверного моста чипсета Intel 815EP, содержащего (среди всего прочего) контроллер памяти

Рисунок 12 815ep_chipset_photo.jpg Внешний вид чипсета Intel 815EP

Рисунок 13 845-northbridge.jpg Этот же чипсет на материнской плате. Северный мост традиционно украшен радиатором
До сих пор мы рассматривали и шинный контроллер, и контроллер памяти как черные ящики. Сейчас же настало время снять с них крышку и изучить их внутренности. Дабы автора не объявили в излишней любви к Intel, сделаем это на примере чипсета AMD 750, попутно отметив, что по качеству документации собственных чипсетов AMD значительно превосходит своих конкурентов.
Контроллер системной шины, отвечающий за обработку запросов и перемещение данных между процессором и чипсетом, состоит из следующих функциональных компонентов: трансфера данных
(Processor Source Synch Clock Transceiver), планировщика запросов (command queue CQ), контроллера очередей запросов (control system queue CSQ) и агента транзакций (transaction combiner agent XCA). Остальные компоненты контроллера шины, присутствующие на рис. 0х28 необходимы для поддержки зондовой отладки, которая к обсуждаемой теме не относится, а потому здесь не рассматривается.
Трансфер данных – в каком-то высшем смысле представляет собой "голый" контроллер шины, понимающий шинный протокол и берущий на себя все заботы по общению с процессором. Полученные от процессора запросы передаются планировщику запросов, откуда они отправляются соответствующим агентам по мере их освобождения.
Ответы агентов сохраняются в трех раздельных очередях: очереди чтения (SysDC Read Queue SRQ), очереди записи памяти (Memory Write Queue) и очереди записи шины PCI (PCI/A-PCI Write Queue AWQ). Обратите внимание: в данном случае речь идет о записи/чтении в процессор, а не наоборот! Т.е. очередь записи памяти хранит данные, передаваемые из памяти в процессор, но не записываемые процессором в память!
Агент транзакций (transaction combiner agent XCA) извлекает содержимое очередей и преобразует их в командные пакеты, которые передаются трансферу данных для отправки в процессор. Если же все очереди пусты, процессору передается команда NOP.
Планировщик запросов памяти (Memory Request Organizer MRO) принимает заказы на чтение/запись памяти сразу от трех устройств: контроллера шины, шины PCI и порта AGP, и стремиться обслужить каждого из своих клиентов максимально эффективно, что совсем не просто (память-то одна!).
Арбитр очереди памяти (Memory Queue Arbiter MQA) помещает всех клиентов в кольцевую очередь (round-robin RBN) и обрабатывает по одной транзакции за такт, в дополнение к этому преобразуя физический адрес ячейки в тройку чисел: банк DRAM, номер строки и колонки. Обработанные транзакции помещаются в одну из нескольких очередей. В чипсете AMD 760 их пять – четыре очереди по четыре элемента на чтение (MRQ0 – MRQ3) и одна на шесть элементов (MWQ) – на запись.
В данном случае под "чтением" имеется в виду чтение из памяти, а под "записью", соответственно, запись в память.
Каждая из очередей чтения хранит запросы, предназначенные исключительно для "своего" банка памяти, благодаря чему при циклической выборке из очередей (этим занимается агент RBN), регенерация банков выполняется параллельно с обработкой других запросов.
Контроллер памяти (Memory Controller MCT) отвечает за физическую поддержку модулей оперативной памяти, установленных на компьютере (в чипсете AMD 760 этим занимается SDRAM Memory Controller – SMC, более поздние чипсеты умеют работать с DDR и Rambus-памятью). Он же отвечает за инициализацию, регенерацию микросхем памяти и ее конфигурирование – установку задержек RAS to CAS Delay, CAS Delay, RAS Precharge, выбор рабочей тактовой частоты и др.
Арбитр запросов к памяти (Memory Request Arbiter MRA) – принимает запросы на чтение/запись памяти, поступающие от MRO и AGP, и передает их SMC. Передача одного запроса занимает один такт.
Данные, записываемые в память, извлекаются из очереди SRQ контроллера системной шины, а данные, читаемые из памяти отправляются в очередь MWQ, откуда они в последствии передаются процессору.
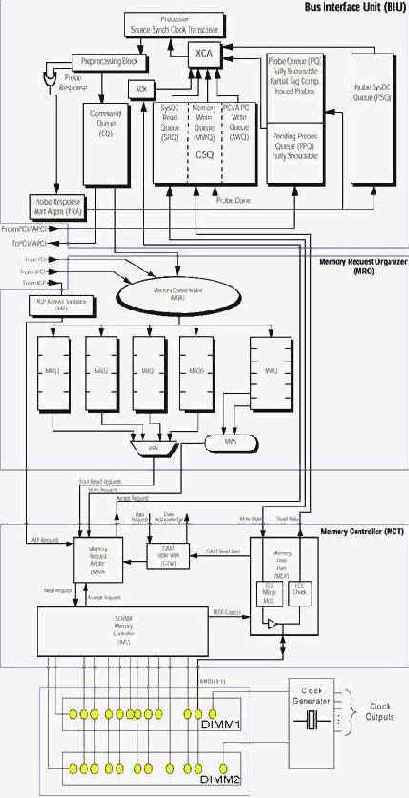
Рисунок 14 0x28 Устройство механизма взаимодействия с памятью в чипсете AMD 750